Cross Dataset References - Quickstart
A step-by-step guide to getting started with Shared Content with Cross-Dataset References in your Sanity Studio.
A powerful tool in your Shared Content toolbox is the crossDatasetReference schema type. This article provides a step-by-step walkthrough of how to get started using it in the studio. For more background on cross-dataset references, please refer to the more in-depth introductory article and the schema type reference.
Paid feature
Shared Content with Cross-Dataset References is an enterprise feature. Use our contact form to start a conversation with our sales team to enable your project to use this feature.
This article presumes that:
- You have access to two different datasets within a single project you’d like to connect
- That both of those datasets belong to projects on an enterprise plan and have the shared content feature enabled
- That the studios you intend to use to interact with these datasets are updated to
v2.34.2or later - That you have some prior experience with Sanity and are familiar with concepts such as the studio, datasets, and projects
For the remainder of this guide, we’ll refer to the dataset that will be doing the referencing as the referencing dataset, and to the dataset that has the document type that will be referred to as the referenced dataset.
Let’s go!
- Navigate once more to the project folder for the studio you intend to use with your referencing dataset. Run
sanity startagain to start up the dev server. (Or, more likely, just keep it running unless you shut it down earlier.) - Open the project folder in your favorite code editor, and navigate to the location where you want your new
crossDatasetReferencefield to show up. You can make a new schema, or make some room in one you’ve already written. - Once you’ve decided where you want your field, add the following code, substituting the placeholder values for your own.
{
title: 'Reference to documents in a another dataset',
name: 'myCoolField',
type: 'crossDatasetReference',
dataset: '<name-of-other-dataset>',
to: [
{
type: '<blogPostInTargetDataset>',
preview: {
select: {
title: 'title',
media: 'heroImage',
},
},
},
],
}- Let’s go through the code line by line:
- The
titleandnamefields, you may give whatever values you’d like.nameis required,titleis optional, as always. - The
typeis required and must becrossDatasetReference. datasetis required and should be given the appropriate values from your referenced dataset.- The
tofield should have an array of the document types you’d like to be able to reference in your referenced dataset. You can have multiple types defined, but only from one dataset per field.- Each entry in the
toarray is an object specifying thetypeof documents we’re interested in and which of its fields we should use for search and previews, as defined by thepreviewfield.
- Each entry in the
- These are the required fields for any
crossDatasetReferencefield, but there are several more! Read all about them here!
- The
- Save your work, and navigate to the appropriate content type in your studio. You should see something like this:
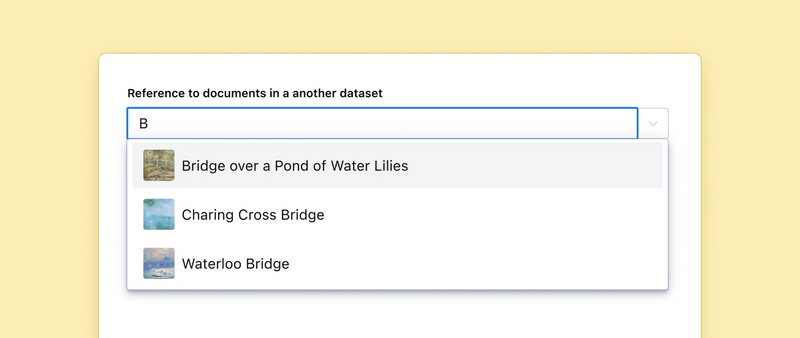
// Results include the name of the origin dataset
{
_type: 'crossDatasetReference',
_ref: 'id-of-reference-document',
_dataset: 'name-of-dataset',
}Cross-dataset references work similarly to regular references, except that dereferencing is unidirectional. You can read more about this in the main article on cross-dataset references, but in short, it means that expanding references using the -> operator works as you'd might expect, but using other methods such as the references() function will not work.
// Dereferencing using -> works as normal
*[_type == 'crossDatasetReferringDocument']{
// Expand entire referenced document
personFromDatasetB->,
// Expand projection of certain fields
"personDetails": personFromDatasetB->{
name,
jobTitle,
awards->name
}
}// This is a NOT SUPPORTED query
*[_type == 'crossDatasetReferringDocument']{
// Expand entire referenced document
personFromDatasetB->,
// Expand projection of certain fields
"personDetails": personFromDatasetB->{
name,
jobTitle,
"awards": *[_type == "awards" && references(^._id)] // <== here the reference function will not work for a cross-dataset reference
}
}