Getting started
Getting started with Sanity
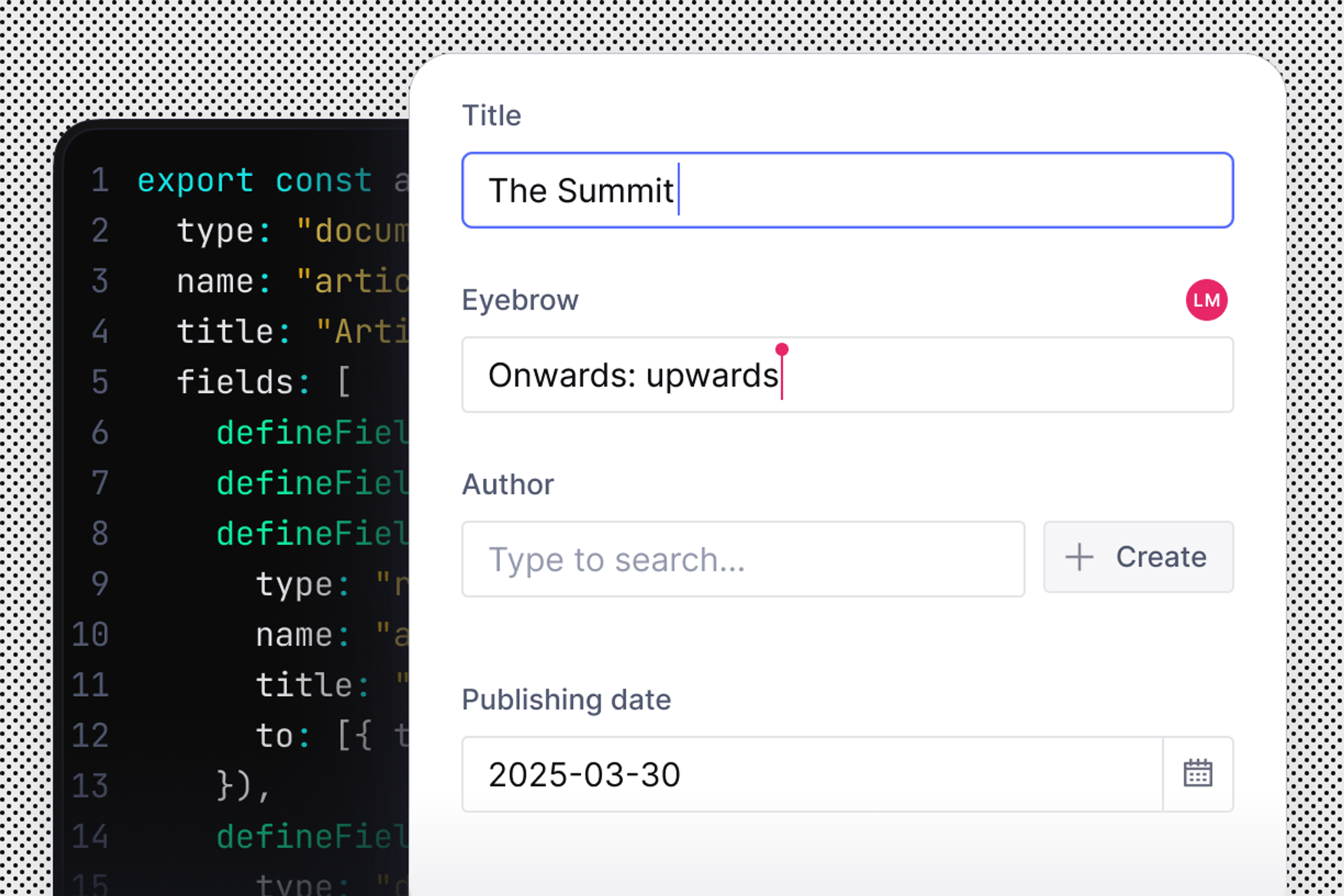
Sanity is a fully customizeable all-code backend for all your content-driven websites and apps—their builders and creators.
From here you can explore the different ways of getting started: framework-specific quickstarts, templates, courses, or exploring the documentation.