
Make your first contribution to the Sanity Ecosystem
Contribute to the Sanity Ecosystem

Bryan Robinson
This guide walks through how to use GROQ to audit a documentation site with user-generated feedback. Learn how to query relationships, use sub-filters, as well as functions like count and order to get a prioritized list of articles that need your attention.

Every documentation article has a job to do and can stand behind you getting your job done. We risk ruining someone's day with a substandard article. With that in mind, Sanity.io's docs have a form at the bottom of each article that asks how useful you found it. After choosing an option, you're prompted to leave a comment to help us improve it.
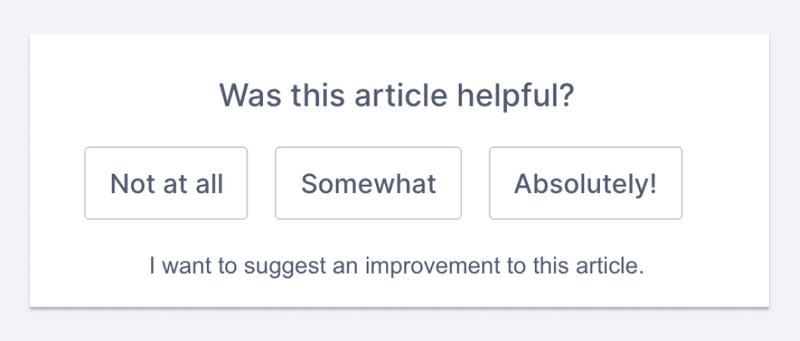
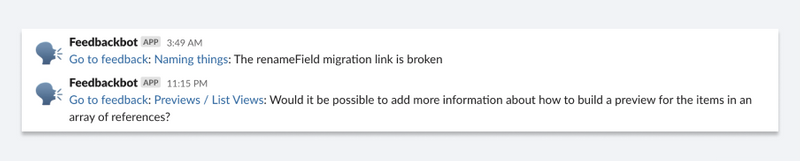
This data is then ingested into Sanity.io's content lake as a feedback document type with a reference to the article. It even posts a message in our Slack! We regularly review the feedback, and the comments are helpful and provide a ton of insight.
I'm currently going through our documentation to update, refine, and restructure it. I want to make sure it's up to date but also as helpful as possible. There are a lot of articles, so where should I start? How do I find the articles most in need of improvement?
I started by collecting some qualitative data. I talked to new community members and new team members. Then, I remembered this treasure trove of data right at my fingertips, one GROQ query away.
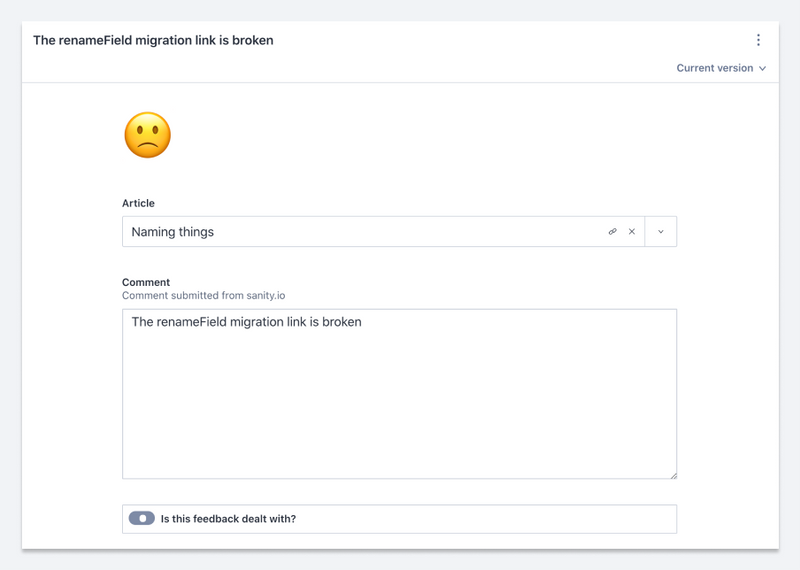
Before we dive into the GROQ queries, let's take a look at how the data is built. We have a schema type that provides the admin experience for the data we collect from the form mentioned above.
export default {
title: 'Feedback',
name: 'feedback',
type: 'document',
fields: [
{
title: 'Rating',
name: 'rating',
type: 'number',
},
{
title: 'Article',
name: 'article',
type: 'reference',
weak: true,
to: [{type: 'article'}, {type: 'schemaType'}, {type: 'helpArticle'}]
},
{
title: 'Comment',
name: 'comment',
type: 'text',
description: 'Comment submitted from sanity.io'
},
{
name: 'done',
type: 'boolean',
title: 'Is this feedback dealt with?'
},
{
name: 'notes',
type: 'text',
title: 'Internal notes',
description: 'What did we do with this feedback?'
}
]
}The rating field is a number, which will allow us to do some helpful math to rate our articles. The articles themselves are references to schema types that have the feedback form. This helps us move about the studio while working on feedback, but will also power the joins we'll do in GROQ to rate articles.
We also have some internal fields that allow us to keep track of the feedback and what we've done. The done boolean field lets us sort by the feedback already fixed, and the notes field lets us describe what we did to fix the feedback.
I had the data. That didn't mean it was ready. We used the rating system to help guide our workflow on feedback submissions. We needed to do some introspection with that information.
Our first challenge is to join feedback items to their articles. Since the feedback is its own document type, we need to do a join to make this happen.
*[_type == "article"]{
"ratings": *[ _type == "feedback" && ^._id == article._ref ].rating,
title
}
// Response
[
{
"ratings": [
1,
1,
1,
0,
// ...
],
"title": "Command line interface"
},
// ...
]This query returns all articles. It then creates a new "ratings" property that gets all feedback documents that reference the _id from the current article. Instead of nesting our rating, we return it directly in the ratings array by appending it to the filter (.rating).
Now, we have an array of articles showing a title and an array of rating scores. In our case, we stored these as 1 for "Absolutely!" helpful; 0 for "Somewhat" helpful; and -1 for "Not at all" helpful.
This shows the ratings, but it's not exactly insightful. I still have to scan each article... we can do better.
Now that we have the ratings, we can assign a stronger set of values and create an overall score for an article.
To do this, we need to decide on a methodology for thinking about the scores. For the first pass, I wanted to keep things simple. I decided that "Absolutely" was +1, "Somewhat" was +0.5, and "Not at all" was -1.
Your mileage may vary on this methodology. It's important to do qualitative work, as well as quantitative.
In our case, the "neutral" case was often positive sentiment, with an improvement suggestion. That seemed to warrant a small positive increase, though not as large as "Absolutely."
When scoring your own feedback, always view it through a qualitative lens.
To use our ratings, we need to run our returned values through another projection.
*[_type == "article"]{
"ratings": *[_type == "feedback" && ^._id == article._ref].rating,
title
}{
"goodScore": count(ratings[@ == 1]),
"badScore": count(ratings[@ == -1]) * -1,
"neutralScore": count(ratings[@ == 0]) * 0.5,
title
}
// Response
[
{
"badScore": -13,
"goodScore": 11,
"neutralScore": 6.5,
"title": "Command line interface"
},
{
"badScore": -7,
"goodScore": 3,
"neutralScore": 5,
"title": "Parts"
},
// ...
]In this query, we return a simplified document object without displaying the large ratings array anymore. We return our new score values and the article title.
We generate each score value from the count() function. We pass a filter to the function to see how many of each rating there are. Since this leaves us with the number of ratings, we need to do a bit of math to get the accumulated scores.
Filter logic can be applied to any array. In many GROQ examples, you'll see filters applied to entire datasets, but this isn't necessary. In this example, we're filtering the ratings array.
For goodScore, the count is enough since its rating value is 1. For badScore we need to multiply that value by -1, and for the neutralScore, we multiply it by 0.5.
At this point, we have everything we need to give our article a score. The score is an aggregate rating based on a combined good + neutral + bad score.
*[_type == "article"]{
"ratings": *[_type == "feedback" && ^._id == article._ref].rating,
title
}{
"goodScore": count(ratings[@ == 1]),
"badScore": count(ratings[@ == -1]) * -1,
"neutralScore": count(ratings[@ == 0]) * 0.5,
title
}{
...,
"aggregate": goodScore + neutralScore + badScore
}
// Response
[
{
"aggregate": 4.5,
"badScore": -13,
"goodScore": 11,
"neutralScore": 6.5,
"title": "Command line interface"
},
// ...
]This is definitely more scannable than a list of ratings, but let's take it another step. Let's sort articles by the aggregate score to find the lowest scores and work on those first.
*[_type == "article"]{
"ratings": *[_type == "feedback" && ^._id == article._ref].rating,
title
}{
"goodScore": count(ratings[@ == 1]),
"badScore": count(ratings[@ == -1]) * -1,
"neutralScore": count(ratings[@ == 0]) * 0.5,
title
}{
...,
"aggregate": goodScore + neutralScore + badScore
} | order(aggregate asc)By ordering by the aggregate score ascending, we get our lowest value scores first. This gives us an ordered list of articles that need work.
So, we have a list of articles with a lifetime aggregate score. The problem is, we are actively working on improving the docs based on this feedback. This score doesn't take that into account.
If someone finds an article hard to understand, and we rewrite it based on that feedback, does that rating still make sense? Probably not.

Luckily, our workflow has a field labeled "Is this feedback dealt with?" This boolean field lets us mark off any feedback that we've solved. Let's modify the query to remove those items from the negative score.
*[_type == "article"]{
"ratings": *[_type == "feedback" && ^._id == article._ref]{rating, done},
title
}{
"goodScore": count(ratings[rating == 1]),
"badScore": count(ratings[rating == -1 && done !=true]) * -1,
"neutralScore": count(ratings[rating == 0]) * 0.5,
title
}{
...,
"aggregate": goodScore + neutralScore + badScore
} | order(aggregate asc)We need to pass the done status to our second projection. Now, instead of our ratings array containing only the rating, we need to include the done value, as well. This changes our filters a bit for our score properties. The @ operator becomes the rating variable.
Our badScore filter needs to check if the done value is NOT true. This will account for both the null state AND the false state.
Even if we don't handle every piece of feedback, the docs change. Time is a variable here. With that in mind, we can also gate our query around a start and end date.
We'll use parameters for this, to make this ready to port to a frontend
*[_type == "article"]{
"ratings": *[
_type == "feedback"
&& ^._id == article._ref
&& _createdAt > $startDate
&& _createdAt <= $endDate
]{rating, done},
title
}{
// ... Rest of our projections
}
// Params
{
"startDate": "2021-01-01",
"endDate": "2021-04-30"
}Our ratings query now checks the articles _createdAt property against a "user-defined" start and end date. This allows us to see articles that are getting better over time or worse—an important feature for a living content set.
This is working out well on my path to improve our documentation, but it's far from the only use case for Content Lake.
When you augment your content with various forms of data, you can create custom metrics. You can use these metrics to figure out what content works and what needs help.
What sorts of queries can your content handle? What data can you attach to your content to make interesting connections? Create snippets and projects in the Exchange to show how a content-is-data mindset helps you and your editors.
Sanity replaces rigid content systems with a developer-first operating system. Define schemas in TypeScript, customize the editor with React, and deliver content anywhere with GROQ. Your team ships in minutes while you focus on building features, not maintaining infrastructure.
Sanity scales from weekend projects to enterprise needs and is used by companies like Puma, AT&T, Burger King, Tata, and Figma.
Contribute to the Sanity Ecosystem

Turn your Sanity and Vercel project into a reusable Starter template

Create three different custom diff components to visually show changes to data in your documents.

Turn your Sanity project into a starter that anyone in the community can use with 1 click.