Shared Content: Accelerate Content Velocity from a Single Source of Truth
Accelerate content creation by sharing the work others have done across your organization.

Simen Svale
Co-founder and CTO at Sanity
Published
Having a single source of truth for every bit of content is the best gift you can give your teams. Enterprise organizations often have different teams working with different content across channels, geographies, and markets.
In other CMSes, teams often create similar pieces of content without communicating with one another, building up content debt. Customers will begin to mistrust your brand as their expectations are not met when navigating your content experience.
In contrast, when content can easily be reused, it helps teams develop experiences faster, unlock creativity, and free up time for people to work on what matters.
Now, enterprise customers have a solution to reduce content debt and enable companies to reuse and deliver content faster to their audiences: Shared Content.
If you are an existing enterprise customer, reach out to your customer success manager to enable this feature on your project(s). Explore our enterprise offering here.
Shared Content in Practice
Let’s take a look at how Shared Content can benefit an enterprise such as a multi-brand, consumer goods company. You may have different digital teams working on individual brands that tie back to the main consumer packaged good conglomerate - a food brand, health brand, lifestyle brand, and other sub-brands. There may also be one to many digital teams responsible for the corporate brand and content, such as common mission statements, logos, and other assets that would be related to the subbrands that the main corporate entity supports.
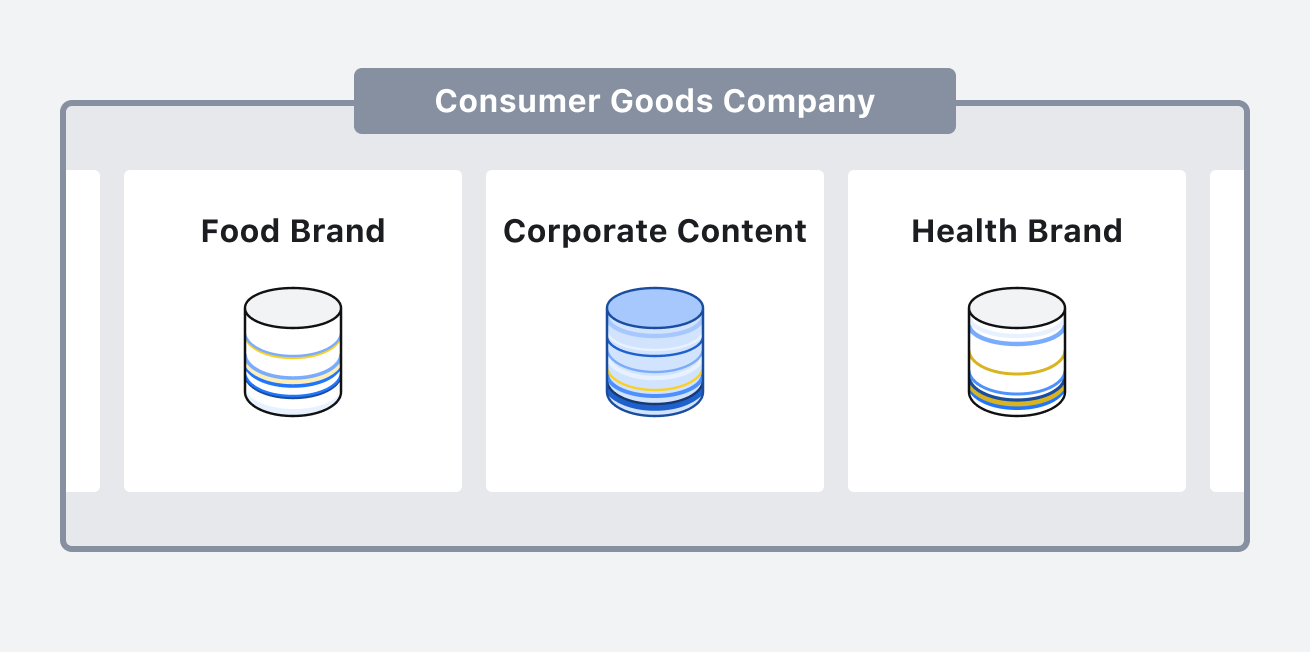
In most CMSes, doing something relatively simple like updating corporate logos or common product information across all the sub-brands and sites which reference that content could wind up taking hours or even days (and risking errors and inconsistency). Teams would wind up searching across many disparate sources of truth, copy-pasting the information over and over again. Checking and double-checking, fixing all the mistakes. For the sake of speed, teams would build up content debt by accepting wording and terminology errors.

With Sanity and Shared Content, that slog disappears. Every team is able to pull in and use content from a central source of truth, without copying anything. Change the product information at the source, and it is immediately reflected everywhere you need it to be, across all channels. By default, Sanity will prevent team members from accidentally deleting documents that have references to them. This prevents editors from unintentionally breaking things and allows developers to build with more confidence. With Shared Content, complex copy changes can be done once and shared everywhere within an organization.
As Easy as Making a Reference
Shared Content enables editors to reference content across two different datasets within a Sanity project. You can think of a dataset as a database where all of your content is stored. While most developers opt to designate datasets by environment (development, test, or production), Enterprise organizations may organize datasets by geography (es, no, etc), product area (products, brand, legal), or in some other way. Shared Content enables the team working on product data to make references to legal information that may exist in another dataset.
Organizing content in this way helps larger organizations develop more efficient workflows. For example, developers can mint API keys distinct for access to product data only, or they can create custom roles that only have access to legal copy.
References across datasets (defined as a new schema type called crossDatasetReference) work mostly the same as references within a dataset:
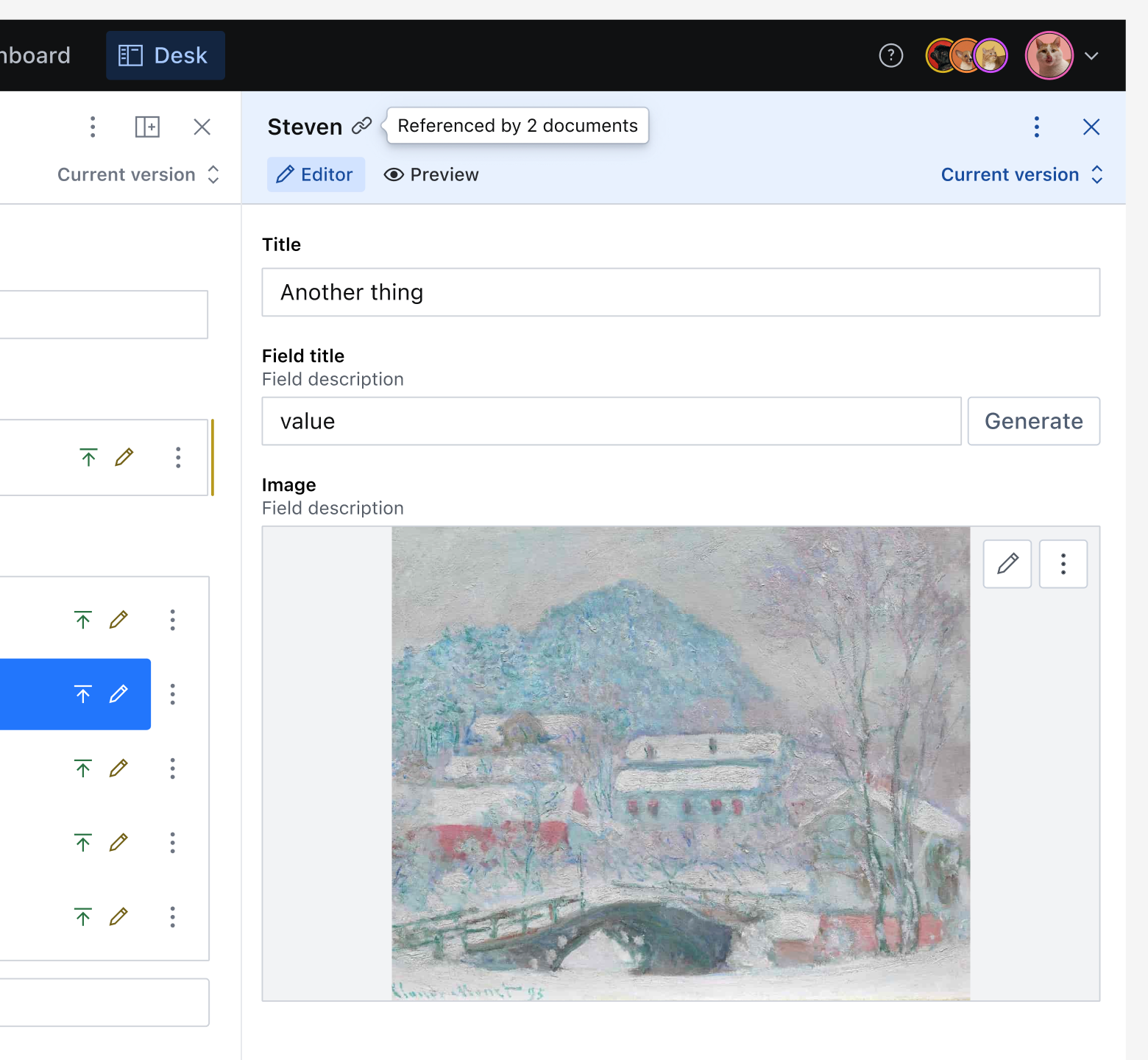
- Customizable previews: A referenced document within another dataset still renders a preview of the reference within the parent document, including any featured images or subtitles.
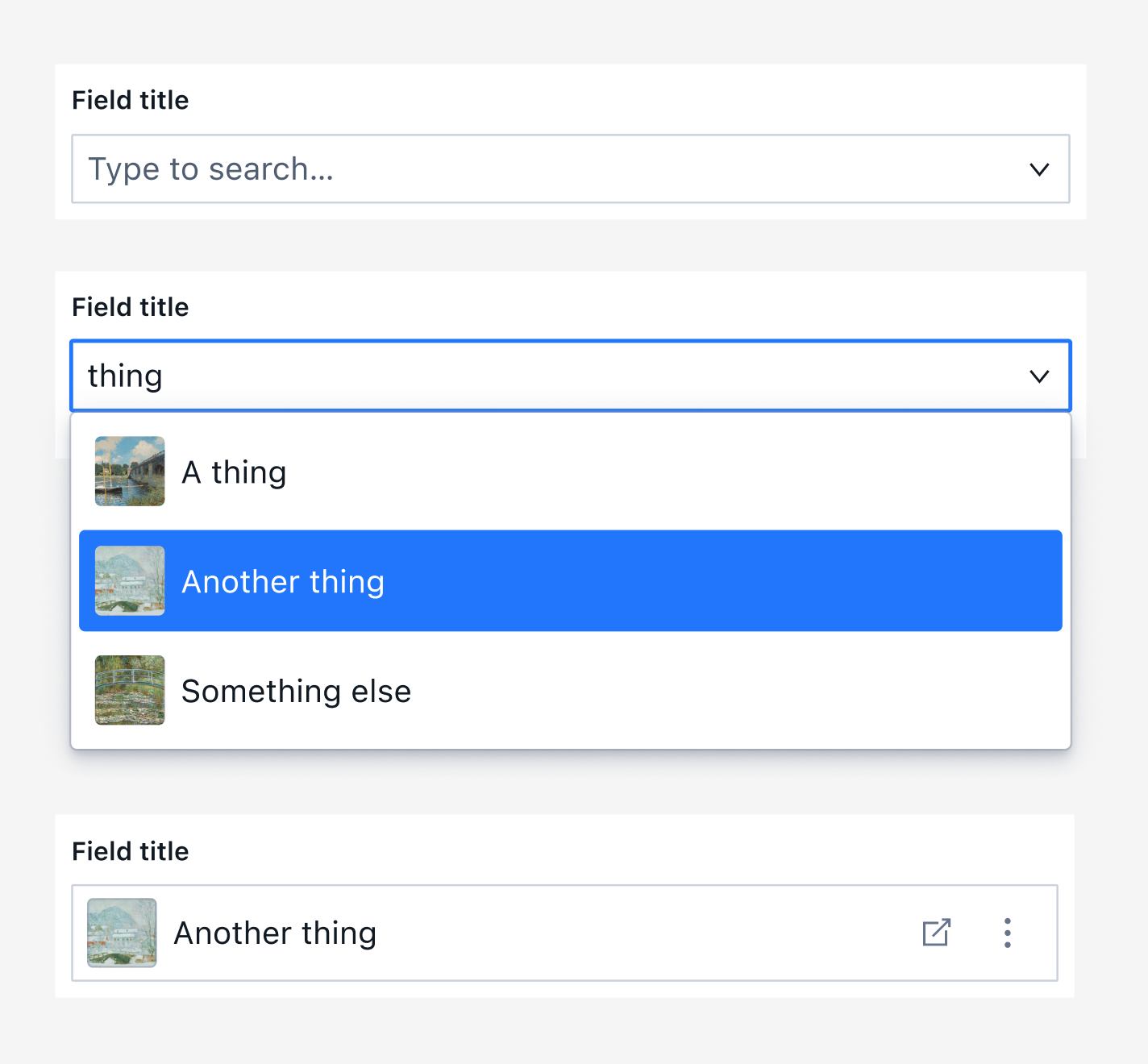
- Quick access: Editors can jump to the referenced document and make changes if needed, so long as they have access to the document within that dataset.
- GROQ de-referencing: You can unpack a Shared Content reference in GROQ. At this time, Shared Content is not supported for GraphQL based schemas.
- Editor support: If an editor attempts to delete a document that is referenced by another document in a different dataset (via Shared Content), Sanity warns them before allowing the operation to continue.
Get Started with Shared Content
If you’re currently a Sanity enterprise customer, contact your dedicated customer success manager to learn more on how to enable shared content on your project.
Once it’s been enabled, your developers can implement the new crossDatasetReference type within your project schema. In this first release, you can create reference fields to content within the same project. Read documentation on this new crossDatasetReference type. There are some slight differences as compared to the reference type, which are discussed in the article.
We’ll keep expanding the scope of Shared Content in the future, and we look forward to seeing how you use Structured Content to eliminate content debt within your business.
If you are an existing Sanity customer and want to explore our enterprise offering, which includes capabilities such as custom roles, multi-project invoicing, and dedicated infrastructure, learn more here.