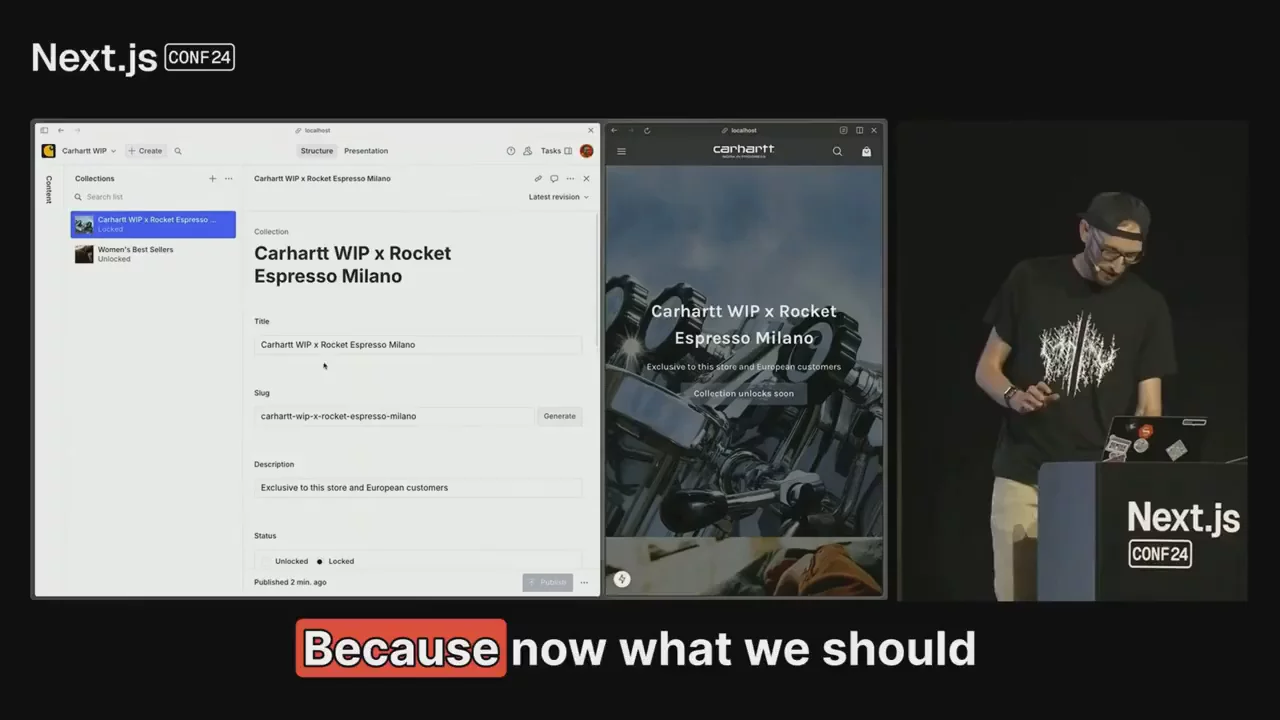
Your content is now Live by default
Caching headaches cured forever. Deliver real-time updates, at scale, with fresh content, for everyone. Available now!

Simen Svale
Co-founder and CTO at Sanity

Knut Melvær
Principal Developer Marketing Manager
Published
Ever had the "Error Establishing a Database Connection: Too Many Connections" message when your site is under heavy load or played whack-a-mole with cache invalidation?
You deploy a critical content update, but you're never quite sure when it will actually hit the site. Maybe you have an mystical web of timeouts, webhooks, and revalidation tags; only to still be refreshing the page multiple times for your changes to be live.
This is why we've developed the Live Content API to make it easy to build live-by-default applications that scale to millions of visitors with just a few lines of code. Like three-ish.
The Live Content API is available in beta, and you can try it now in our Next.js starter, explore the documentation, or watch our recent Next.js Conf talk.
The perfect storm: When caching breaks down
Imagine this scenario: You're running an e-commerce site, and a high-profile entrepreneur called Kim just dropped a instagram post about your latest product. Suddenly, thousands of eager customers flood your site. This is your moment to shine – but it's also when traditional caching solutions start to crumble.
What are your choices?
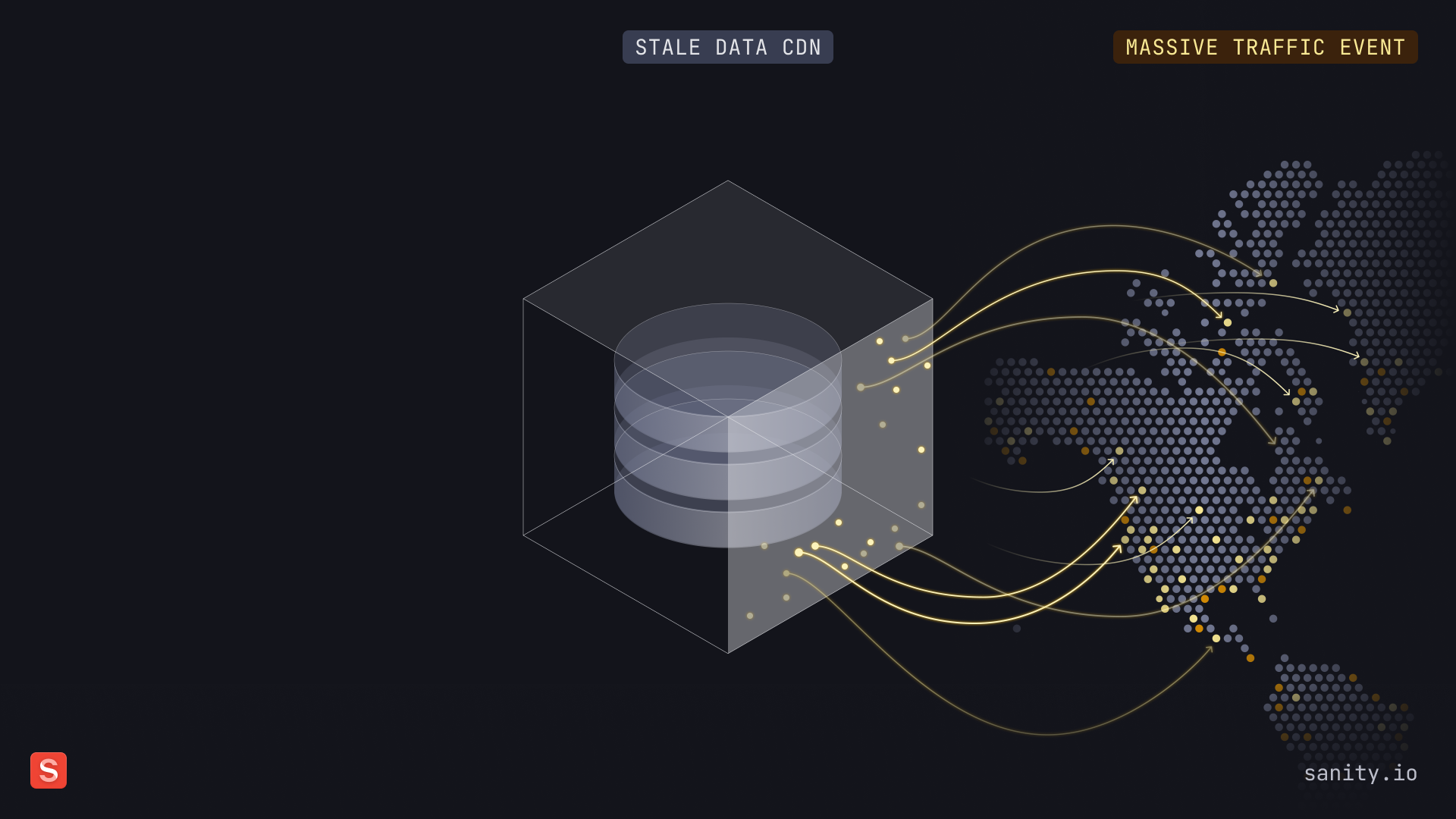
You're caught in an impossible situation:
- If you keep your CDN cached, visitors might see you feature products that are sold out, letting them try to buy things that are already sold out.
- If you invalidate your cache to ensure fresh content, you're effectively DDOSing on your infrastructure
- Either way, you're likely pouring money into emergency infrastructure scaling or keeping your team up at night monitoring systems. No bueno.

To understand why these scenarios are so challenging to handle with traditional approaches, we need to take a step back and look at how content delivery has evolved on the web.
How content delivery actually works
The web has come a long way from its static beginnings, but many of our fundamental patterns for delivering content remain unchanged. Understanding these patterns helps explain why we're still struggling with the same caching problems decades later.
The classic request-response pattern
The request and response pattern is how we fetch content on the web. When you click a link or type a URL, your browser sends a request to the server hosting the website. The server responds with the requested content, which your browser renders. Simple enough!
But here's something to consider: you now have a cached version of that site in your browser. We've been trained to revalidate this cache by hitting the reload button – and as developers, we even use special hotkeys to make extra sure we're bypassing all cache layers. Hopefully, we'll get fresh content from the server. Right?
This pattern worked well for the early web, but as applications became more dynamic and interactive, we needed more sophisticated solutions.
How we got here
The web was built for a simple client/server model. Take your vanilla WordPress install: when a visitor requests a blog post, WordPress runs PHP code on the server for every visitor. The template code makes a database request, generates HTML by inserting content into the template, and returns this as a response.
This model works fine until your site gets popular. With many concurrent visitors, it becomes resource-intensive and can crash your server. The traditional solution? Add caching plugins. But suddenly, your users aren't guaranteed to get fresh content, even with aggressive cache busting.
As these limitations became more apparent, the industry began moving toward more sophisticated architectures and frameworks.
Modern web caching
When we started to build with decoupled frontends consuming API data, frameworks like Next.js introduced sophisticated caching mechanisms. For example, Next.js typically handles data fetching in components and maps that to children components:
import { client } from "@/sanity/client";
import { PRODUCTS_QUERY } from "@/sanity/queries";
export default async function Page() {
const products = await client.fetch(PRODUCTS_QUERY);
return (
<ul>
{
products.map((product) => (
<li key={product._id}>
<a href={`/product/${product.slug}`}>{product.title}</a>
</li>
))
}
</ul>
);
}Next.js optimizes performance through features like prefetching content for anticipated routes, typically implemented through special Link components that enable quick client-side renders:
import Link from "next/link";
import { client } from "@/sanity/client";
import { PRODUCTS_QUERY } from "@/sanity/queries";
export default async function Page() {
const products = await client.fetch(PRODUCTS_QUERY);
return (
<ul>
{
products.map((product) => (
<li key={product._id}>
<Link href={`/product/${product.slug}`}>{product.title}</Link>
</li>
))
}
</ul>
);
}For optimal performance, Next.js uses various caching strategies, from static JSON files bundled with the application to specialized data cache layers depending on your hosting environment.
But even these modern solutions come with their own set of challenges and complexities.
The caching confusion era
Caching particularly impossible when it breaks our assumptions about how fetching works. Take Next.js 13 (the one with the App router) introducing aggressive default caching on Vercel. The cache lived outside the Next.js app, so you could redeploy without necessarily busting the cache – great for performance, confusing for developers who didn't read the fine print.
This is improved in Next.js 15 with new APIs and progressive disclosure through opt-in caching with the "use cache" directive.
But we're still left with fundamental challenges in ensuring users have the freshest content.
These improvements in framework-level caching are significant, but they don't address the problem of delivering real-time updates at scale.
Traditional CDNs aren't built for real time
Content Delivery Networks excel at distributing static content globally. But they weren't designed for today's dynamic content needs:
- Live sports scores that change by the second
- Stock prices that fluctuate continuously
- Breaking news that needs immediate visibility
- E-commerce inventory that updates in real-time
This mismatch between traditional CDN capabilities and modern content delivery needs led us to rethink the entire approach to content distribution.
How we solved it: The technical details
After analyzing these challenges, we realized that solving this problem would require innovation at multiple levels of the stack. Here's how we approached it.
Invalidating graph-based content
Content Lake offers a unique NoSQL document store with referential integrity that can be queried with GROQ. While we've always offered CDN caching for GROQ responses, invalidating cache for graph-based content presents unique challenges.
The flexibility of GROQ querying makes cache invalidation non-trivial. Initially, we used a crude but effective approach: invalidate all cached query responses when any document updated. This worked well enough most of the time – except when it didn't, particularly during high-traffic periods with concurrent content updates.
This experience taught us that we needed a more sophisticated approach to handle real-world scale.
The solution: Opaque surrogate keys, delivered in real time
We developed a fine-grained system to precisely map which queries need invalidation on content updates. Queries are tagged to track exactly what an update will affect. We developed this for granular invalidation of our own CDNs, but we've also made available for invalidating other external like caches, like web browsers, it simple through our new syncTags property in query results.
We've also added throttling measures for high-volume update scenarios, strengthening our global infrastructure's resilience. These sync tags are opaque, making them safe to expose in an external API without authentication.
When someone visits your site, you can safely request the Live Content API to open an event stream to their client. The application matches stream syncTags with query result tags, triggering selective content refetching through the CDN. Updates typically appear within seconds, with a maximum delay of a couple of minutes during periods with a lot of mutations to your dataset.
Talk to us if you are interested in even better performance and higher number of concurrent users.

The result is a system that combines the performance benefits of CDN caching with the immediacy of real-time updates – all while maintaining scalability and reliability.
Making it work with Next.js: Live by default, static by design
When we say "Live by default," we really mean it – but not at the expense of performance or your infrastructure costs. Our Next.js implementation is built on top of revalidateTag and Next.js caching, which means everything stays Incremental Static Regeneration (ISR) and static unless you explicitly opt into dynamic APIs (like cookies, headers, or search params).
Here's what makes this approach special:
Efficient Runtime Model
- The live listener runs in the browser, not on your server
- Updates are push-based, eliminating the need for polling
- When 500 people are on your site and you push an update, all 500 trigger revalidation and refetch the React Server Component (RSC)
- Vercel automatically deduplicates identical requests and data fetches to a single request that all clients listen for
- Content Lake sees just one request, keeping your API costs predictable
Granular Caching
- If your route uses three GROQ queries and only one gets invalidated, only that query refetches
- Other components continue using their cached data
- With Next.js 15's
'use cache'directive, component-level caching becomes even more granular - You only pay for the exact compute required to rerender changed content
Versatile Implementation
- Works seamlessly in
layout.tsx - Can be used in
generateMetadatafor live browser titles - Even supports dynamic favicon updates through
icon.tsx - Full compatibility with Next.js ISR
Cost-Effective
- Eliminates the need for webhooks in high-traffic scenarios
- Much more efficient than using dynamic SSR as an alternative
- Minor increase in Vercel runtime seconds, but we'd say that the value far outweighs the cost
- Three(ish) lines of code to implement
import Link from "next/link";
import { sanityFetch } from "@/sanity/live";
import { PRODUCTS_QUERY } from "@/sanity/queries";
export default async function Page() {
const { data: products } = await sanityFetch({ query: PRODUCTS_QUERY });
return (
<ul>
{
products.map((product) => (
<li key={product._id}>
<Link href={`/product/${product.slug}`}>{product.title}</Link>
</li>
))
}
</ul>
);
}The beauty of this approach is that it's both powerful and pragmatic. You get real-time updates without sacrificing the benefits of static generation, and your infrastructure costs remain predictable and manageable.
Ready to make your app Live by default?
The Live Content API is available in beta on all plans. Here's how you can get started:
- Try it in our Next.js starter
- Watch our Live by default talk from Next.js Conf
- Explore our documentation and vanilla JavaScript example
- Sign up for our upcoming product event for a deep dive
Congratulations, the only hard thing left in computer science is now naming things.