Scoping a new AI Agent? We’ve got the embeddings covered
Large language models change the game for chatbots and other AI agents. Our new Embeddings Index API saves you a step in building your own.

Molly Friederich
Director of Product Marketing at Sanity

Even Westvang
Co-founder and product person at Sanity
Published
Deprecation notice:
The Embeddings Index API described in this post has been deprecated. We recommend migrating to Agent Context, the new native embeddings feature in Sanity.
Even the most patient among us has had that moment of fury when a chatbot just. Doesn’t. Help. Suddenly, you’re leaning into your laptop, saying, “GIVE ME A HUMAN!”
Not exactly the user experience that leads to satisfied, successful users—or increased revenue and reduced costs.
The future looks brighter as we try to find info or get assistance. With Large language models (LLMs) disrupting the legacy chatbot, we stand to get answers that will often be faster—and even better!—than what we get from a customer service or support person. And as they improve user experience, this new breed of AI agent chatbots will increase revenue and decrease operational costs for the companies who build them.
While chatbots of the past rely on rule- and keyword-based logic, AI agent chatbots take advantage of LLMs’ vast knowledge and context to provide truly useful responses. But there’s a catch, of course. An AI agent needs specialized knowledge about your unique organization, offering, and customers. While LLMs know a lot, they don’t know everything and tend to fall short regarding domain expertise.
Enter our latest feature: The Sanity Embeddings Index API, available in beta across the Team, Business, and Enterprise plans. You can use this API to give the AI agents you’re building expertise by exposing it to content you store in the Sanity Content Lake. That means your AI agent can learn from every product detail page, blog post, About Us page, support content, you name it. Best part? As your content within Sanity evolves and grows, your AI agent gets the new information automatically.
Embeddings, what?
While it’s true that AI is all the rage, we’ll take a moment to level-set on what exactly embeddings are and how we use them.
First, why not fine-tune an LLM to give it the domain expertise we referenced earlier? It’s simply not practical for most real-world applications. You’d need massive amounts of training data (which is expensive to produce), and you’d need to fine-tune repeatedly over time as your content changes (and would risk the LLM wouldn’t appropriately “unlearn” old knowledge).
Instead, it is more effective and far less costly to use embeddings indexes, especially for targeted tasks like answering customer questions.
An embedding is a way to represent the meaning of a word, phrase, or entire document as a numerical vector. A vector database uses these to understand how similar language is conceptually. Suffice to say: it’s math. Very useful math that means you can now find related and relevant content based on the meaning of a search query or chatbot question rather than a keyword match.
Sanity’s Embeddings Index API
Of course, as the Content Operating System, our customers store a lot of domain-specific content within Sanity. Everything from e-commerce product information to news and articles from publishers to vast how-to and support documentation.
To save you a step, our new Embeddings Index API gives you a way to give your AI agent access to Sanity-created embeddings indexes. In the latest AI framework for this, Retrieval Augmented Generation (RAG), the Embeddings Index API acts as the retriever that sends context to the LLM (which is the generator).
Sanity-created embeddings capture the meaning of your content to perform tasks like identifying documents about a specific topic. As your corpus of content within Sanity evolves, Sanity will automatically update your indexed embeddings, so the context you give your agent stays current!
AI Engineers can use these embeddings indexes to:
- Quickly build AI agents that understand your business
- Develop sophisticated search and recommendations
- Optimize sequential reasoning in documents
- Retrieve similar content for more nuanced outputs
To curate content helpful for the AI agent tasks they’re solving, you can create multiple indexes per dataset and use GROQ to control what content to include in the embeddings index.
As usual, we've launched this as an API you can build on top of, and in an effort to save developers time we have also shipped:
- The Embeddings Index CLI lets you query, create, list, and delete indexes and keep track of indexing jobs.
- The Embeddings Index UI that you can install in your Studio to manage indexes in your project and do some test queries to see what documents are returned.
And there is one more thing.
Try now: better Studio reference search
While putting together documentation for the new API, we built a demo of the type of value it can bring to customers. Once we did that, making it an official Sanity Studio plugin was a no-brainer.
A huge part of Sanity’s value is storing content as data, which unlocks massive opportunities for connected content and content reuse. As our customers grow and scale, they add more content (and more teammates who create and use it). This growth can make it difficult for all involved to know what references may exist and where to create links, leading to missed opportunities for content reuse and cohesive customer journeys.
Sanity Studio already offers useful reference-level search functionality, but it’s based on text matches. This means your content authors, editors, or operations people only need to know roughly the right search term to use to find the right content.
Now, with the Semantic Reference Search Input plugin, you can use any intuitive search query to find relevant documents to reference. Instead of relying on keywords or tags, it uses an embeddings index to understand the meaning of both your search term and the corpus of potentially relevant content. In fact, before you even start typing, it knows the context of the document you’re in and will prioritize content that’s likely related.
Demo
Here’s an example of using the plugin to find related products for a (pretend) campaign for furniture on sale. Notice how the list is ready with relevant entries even before we start typing:
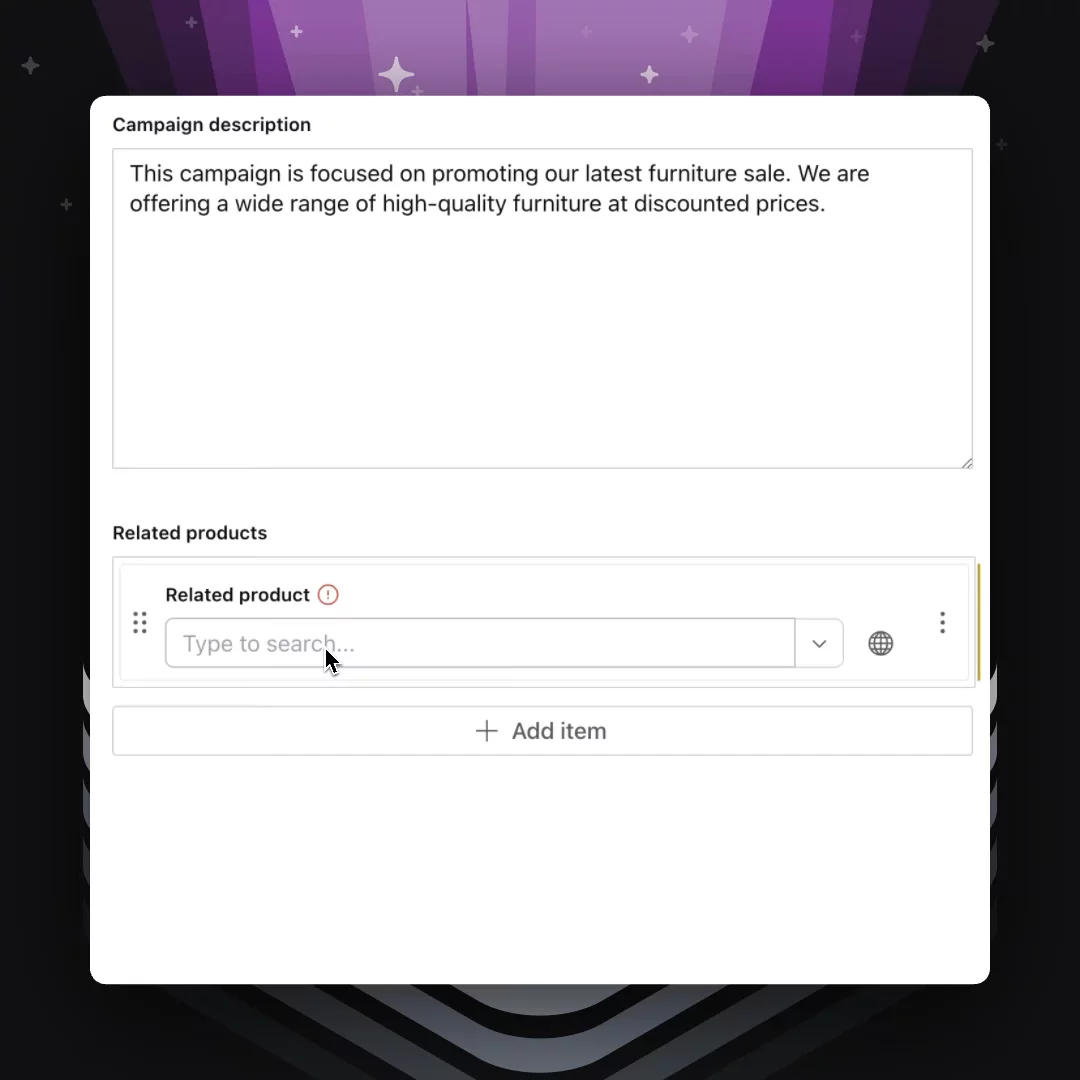
For content creators, this represents massive time savings and higher confidence that they’re surfacing the best possible content as they create references. Alongside Sanity AI Assist, it’s another powerful way to save editors time on time-consuming tasks that eat into more strategic work.
On the road to bigger things…
We didn’t initially set out to create this as a separate feature. But as we experimented with future features and use cases for Sanity with AI-enriched experiences, the need for these embeddings indexes kept coming up as an essential building block for things we know customers are looking to do. Embeddings are like this incredible central building block for authoring the worldview of an LLM.
We will use this feature for our AI experiments and upcoming AI features, and we look forward to learning what you will build with it.
To get started on projects from Teams and up, head over to:
If you want to learn more about how we can help you do more with content, including with the help of LLMs and AI, get in touch with our sales team.