Filters and projections
In Vision, run the following query:
*You’ll be returned every document in the dataset. It’s an impressively fast query but not very useful. You could filter this data down on your front end, but why not let GROQ filter for you?
**[]The characters [] here is an array filter. This query returns the same results as the previous one. This is because our filter is not actually filtering.
You’re likely familiar with working with JavaScript arrays where [] allows us to do an index lookup, and that does work, too
*[0]You have access to all the data that precedes it within the filter. So the GROQ we write in between [] will filter the results of *.
Right now, the most obvious is filtering everything down to just the event type documents. They all share the same value in the _type field. We can add a filter for just this:
event type documents*[_type == "event"]Now we’re seeing fewer documents than "everything," and they all only contain the same type. This is a much more useful query.
_type in a filter. Let’s get every document with a slug, perhaps to populate a sitemap of every page of a website:
_type-free query*[slug.current != null]Back on topic. Currently, there’s no limit on how many documents it returns. We can use another filter to change that.
Here you're performing "array slicing" by only returning three documents based on their index position.
*[_type == "event"][0...3]If your array slice uses two periods .. the right-hand side index will be included in the result. So the below will return four documents instead of three.
... with ..*[_type == "event"][0..3]While the query is fast now, as the project gets more complex and the dataset larger, we should begin to think about optimizing how much data is returned. It is easy to return everything; writing more filters and adjusting how much we return can be faster.
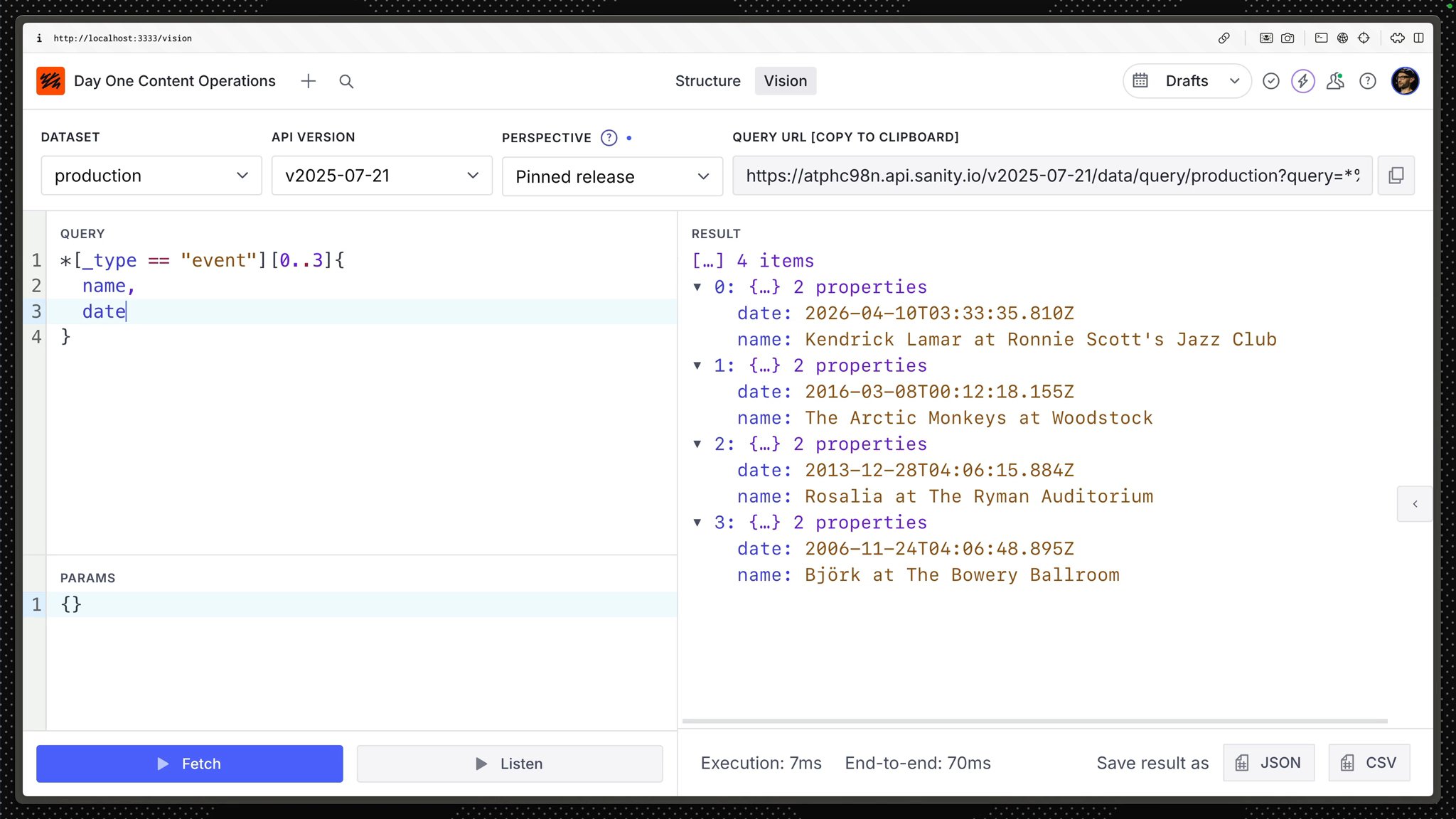
The data returned from a document is defined by its “Projection.” A list of field names will be looked up in each document.
name and date fields from the first three event documents*[_type == "event"][0...3]{ name, date}Much better. You shouldn't return data if you don’t need it.
Naming specific attributes inside a projection also clarifies what data your consuming application depends on.
You can return keys that exist on a document as well as arbitrarily add new keys to the returned value, perhaps calculated by values in the document itself.
For this project, we know that an event is in the past if its date field is older than the now() function. (More on functions in the next exercise.)
Instead of running logic in our front end to differentiate these, we can add the logic to our query.
isPast key*[_type == "event"][0...3]{ name, date, "isPast": date < now()}One more useful operator to know at this point is how to order documents. That is done with a pipe and the GROQ function order.
Take note that the order() function has been placed before the "array slicing" filter. This ensures you order all documents and then return only the top three.
*[_type == "event"]|order(_createdAt desc)[0...3]{ name, date, "isPast": date < now()}GROQ functions are super powerful; let's unpack them in the next exercise.