Get started with Structure Builder API
This is an introduction to important concepts for the Structure Builder API.
Structure Builder is an API meant to help reorganize flows and documents inside of Sanity Studio. This article introduces the central ideas and definitions needed to understand how to use the API. If you want to jump ahead, check out the reference documentation for all API methods and functionality.
Structure builder is useful whenever you want to control how documents are grouped and listed in the studio or for adding additional in-studio previews or content to documents.
Protip
Looking for quick examples of common use cases? See the Structure Builder cheat sheet.
Learning the Structure Builder API
This collection of articles will walk you through all the basics of using Structure Builder to create custom editing experiences.
How does structure builder work?
The Structure Builder API is a collection of classes with methods that you can chain and nest to express how documents should be organized in the Sanity Studio.
export const structure = (S) =>
S.list()
.title('Content')
.items([
S.listItem()
.title('Settings')
.child(
S.document()
.schemaType('siteSettings')
.documentId('siteSettings')
),
...S.documentTypeListItems()
])Notice how the methods are added to each other. For a detailed explanation of this code, read the next article on setting up Structure Builder.
What are collapsable panes?
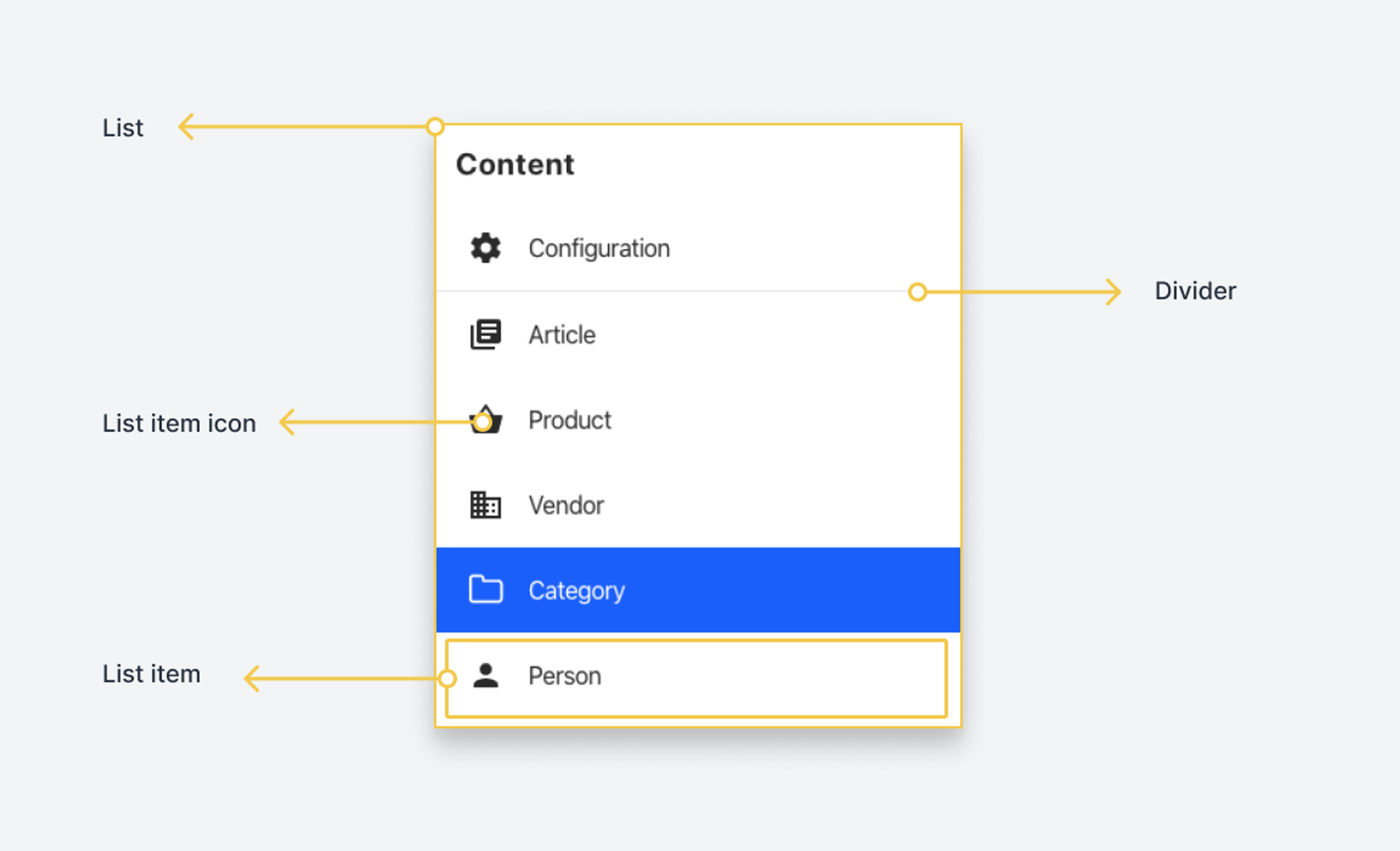
When working with the Structure Builder API, you'll primarily be modifying or creating collapsable panes. These panes are the parts within the Structure tool with a title and contain a list of document types, a list of documents, a form, or a custom component. If you make the window narrower, add more panes in the viewport, or click the title area, they will fold down to make more space within the window. This gives authors a quick way to focus on the right things and keep a visual trail of where they are in the different hierarchies.
There are often items within a pane that may open a new pane. The new pane will open to the right, and the current pane will stack to the left. In the Structure Builder API, the pane immediately following another is commonly referred to as a child. The initial pane shown when the Structure tool opens is called the root pane.
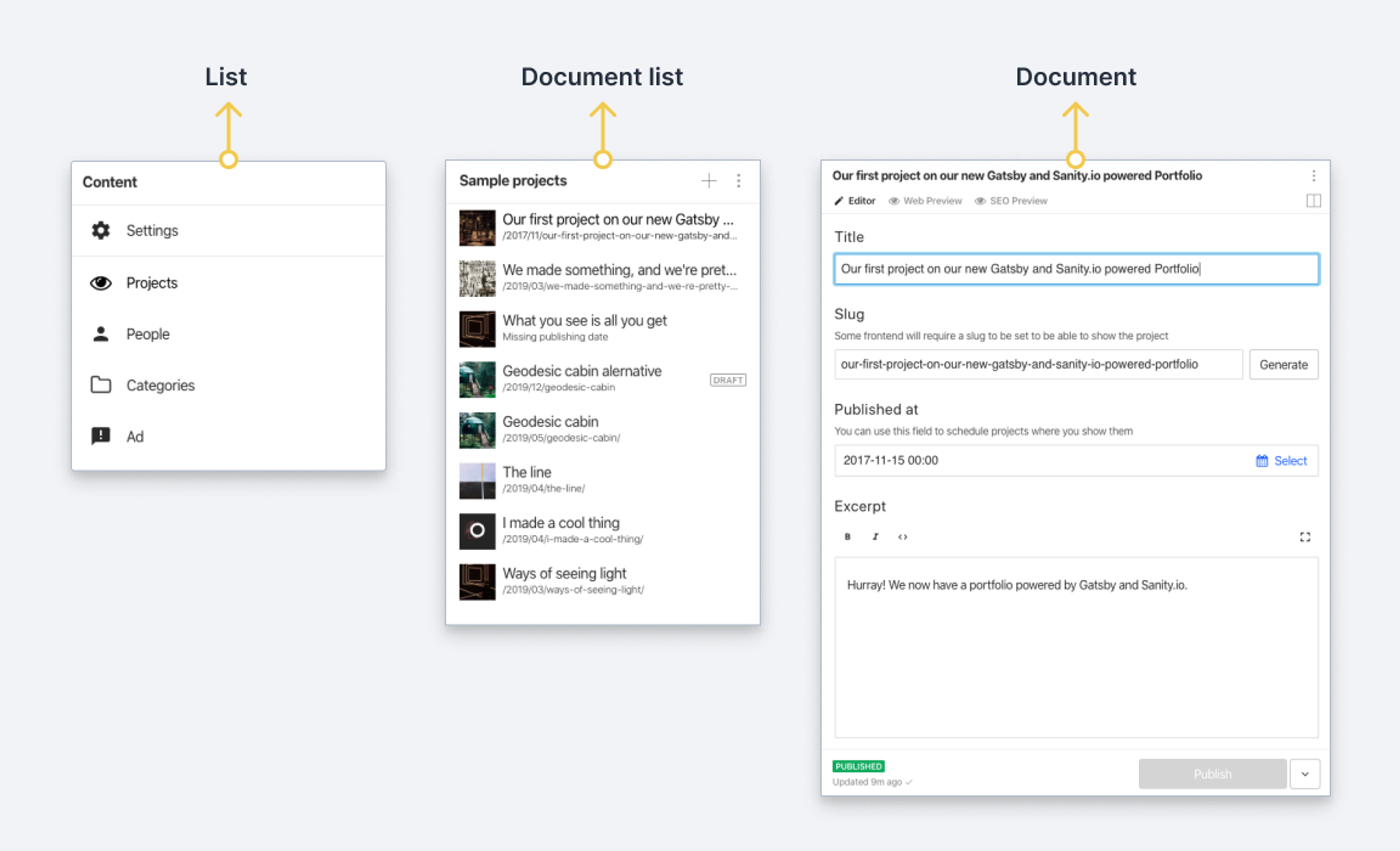
Pane types
There are four types of panes:
- List
- Document list
- Document
- Custom component
List
A list contains one or more list items and is generally considered to be static. An example of this pane type is a list of document types within your schema.
While generally used for static items, a pane can perform asynchronous calls before determining its items. It can be useful if you need more control over how a small set of items should be rendered in the list. If you're listing documents, you should generally always use a document list.
Document list
Optimized for displaying a list of documents, as the name implies. It differs from a regular list in that it does not simply fetch a list of documents on load but also keeps that list up to date with any changes: documents that match its filter that are deleted will disappear, newly created documents will appear, and changes to the titles will be reflected in real-time.
A document list is given a GROQ filter and then builds an optimized query based on the filter and the pane ordering. It then implements an "infinite scrolling" pattern that lazy-loads the properties needed to display the screen's documents.
A document type list is a subset of a document list, which collects documents where the _type property matches a given value (in the schema definition, this is the name you set for the type: 'document'). Document types may also have Initial Value Templates attached to them and certain orderings of their documents.
Document (and views)
A document pane (and its corresponding document node in structure terms) is a component that holds a document’s values and different states (published, draft, historical, displayed). Typically, this will be the editor form with the input fields for the document's data.
It can also be a component that you import and configure with your structure definition. Typically, a view is helpful when you want to contextualize your document values somehow. It can be used for making different types of previews, statistics, checklists, alternative ways of interacting with the document values, or anything you can build with React.
Custom component
You may also implement your pane using a custom React component. The component node can be given a set of options passed as an options property to the actual React component being rendered.
The component is rendered inside the shell of a pane, with the pane header, menu, and actions available for configuration. You will find more information on how to use this in the reference documentation for the structure builder.
Path resolution and URL structure
You can open the same document from multiple paths through a structure. This creates an interesting challenge. Sometimes, you know only the document's ID you want to open, but not necessarily with which of the different paths makes sense to open it. In these cases, the API will make a best-effort calculation to figure this out for you, while the fallback will be to open the document to the right of the root pane.
The Structure Builder API also gives you ways to set a default configuration for a document node that's opened outside of a path. This is useful when you want to ensure that a certain document type always has a set of views accessible.
Child resolvers
Each pane is represented in the URL by an ID. When the studio is first loaded – and on subsequent navigation – the Structure tool looks at the segmented ID in the URL and tries to resolve each ID into a structure node.
It does this by calling the child resolver on the parent node. For example, a common pattern is the document type list leading to a document editor. When an editor clicks on any item within the document type list, it will render a document editor as a child of that list. This is usually represented in the URL by something like documentType;documentId - for instance, book;game-of-thrones represents the book type and a document with an ID of game-of-thrones.
The Structure tool will call the child resolver of the root node in the structure with an argument containing the first segment (book), which will return a document-type list. When that is returned, it will call the child resolver of the document type list with the next segment in the URL (game-of-thrones). This will return the document editor pane for this specific document.
Child resolvers don't necessarily care about the ID of the child. In these cases, it's better to define a static structure node instead of a function returning that structure node since this will help the Structure tool make certain assumptions.
URL state
Most states within the structure are represented in the URL bar. This is why you have to specify an id – often implicit when setting a title – for lists, document nodes, or components. These identifiers are semi-colon-separated in the URL path. Other states within a document node – such as views – can also be parameterized in the URL bar.
This makes it possible to share the Structure tool's exact state more easily between multiple tabs, windows, or users. It also gives you browser history so that editors can use their browser's history affordances to go between different UI states.
Next steps
Now that you have a solid foundation of the concepts and definitions that make Structure Builder work, let's look at implementing a basic override of the default structure in a studio.
Was this page helpful?